TextCNN - сверточные сети для NLP
Published 2 февраля 2025 г. 12:35
Приветстсвую всех любителей нейронных сетей и NLP!
Позвольте представить вам нашего сегодняшнего гостя - архитектуру TextCNN. Само название (по крайней мере первая его часть) говорит о том, что используют её для работы с текстами. Но при чём тут сверточные сети (convolutional neural networks)? Давайте вместе подробнее рассмотрим данную архитектуру и выясним, как сверточные сети позволяют анализировать текст и использовать TextCNN для таких задач как распознавание сентимента и классификации.
Прежде всего давайте вспомним, как происходит обработка текста в нейронных сетях. Когда мы подаем на вход нашей сети текст (желательно предватительно обработанный), каждое слово в нем представляется в виде вектора, который получается при эмбеддинге.
Так мы формируем матрицу n X m, где n - количество слов в тексте, а m - размерность эмбеддинга.

Вот мы и получили первый слой нашей TextCNN! Всё верно, первый слой - слой эмбеддингов. Далее будет кое-что необычное).
В большинстве случаев CNN используется для работы с изображениями (по сути они лежат в основе многих известных сейчас архитектур для анализа изображений). Однако применение данной архитектуры для текстов также не лишено смысла. Не секрет, что благодаря сверточным слоям в изображениях удается выделить основные признаки, с которыми в дальнейшем можно работать. Аналогично и здесь, сверточные слои позволяют выделить n-граммы, которые являются локальными признаками для текста.
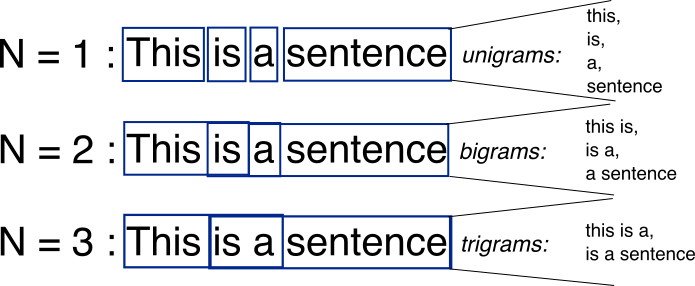
Каждый слой свертки позволяет построить карту признаков (aka feature map), которую в дальнейшем собирают вместе и сжимают с помощью пуллинга (т.е. выделяют наиболее важные признаки).
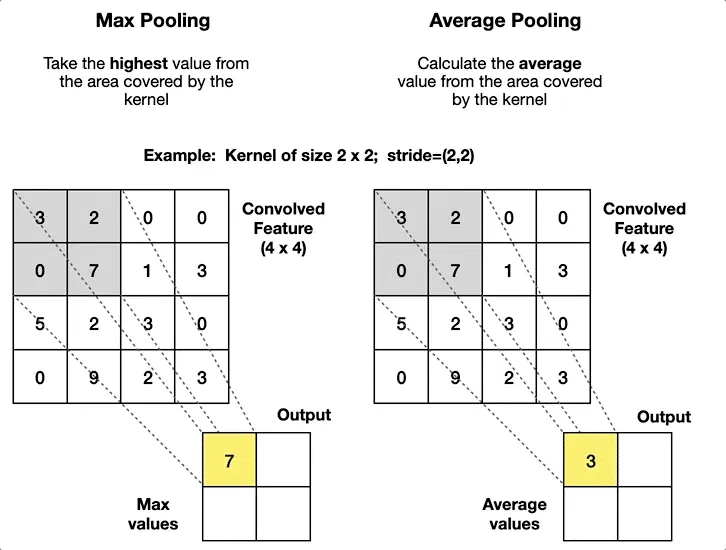
Теперь у нас есть аж 3 слоя: Embedding, Convolutional и Pooling. Кажется, что для классификации чего-то не хватает ψ(._. )>.
Мы забыли про Linear слой! Без него наши старания по построению TextCNN - just a waste of time🙂.
Итак, кажется, мы собрали все необходимые нам компоненты для создания TextCNN модели (ノ*ФωФ)ノ.
PyTorch TextCNN:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes, filter_sizes, num_filters, dropout_prob=0.5):
super(TextCNN, self).__init__()
# 1. Embedding Layer
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 2. Convolutional Layers (разные размеры фильтров)
self.convs = nn.ModuleList([
nn.Conv1d(
in_channels=embed_dim, # Для Conv1D: (batch, embed_dim, seq_len)
out_channels=num_filters,
kernel_size=fs
) for fs in filter_sizes
])
# 3. Dropout
self.dropout = nn.Dropout(dropout_prob)
# 4. Fully Connected Layer
self.fc = nn.Linear(
in_features=num_filters * len(filter_sizes),
out_features=num_classes
)
def forward(self, x):
# x: (batch_size, seq_len)
# Embedding
x = self.embedding(x) # (batch_size, seq_len, embed_dim)
x = x.permute(0, 2, 1) # (batch_size, embed_dim, seq_len) для Conv1D
# Применяем свертки и max-pooling
conv_outputs = []
for conv in self.convs:
# Conv + ReLU
out = F.relu(conv(x)) # (batch_size, num_filters, new_seq_len)
# Max-over-time Pooling
out = F.max_pool1d(out, kernel_size=out.size(2)).squeeze(2) # (batch_size, num_filters)
conv_outputs.append(out)
# Конкатенация выходов всех фильтров
x = torch.cat(conv_outputs, dim=1) # (batch_size, num_filters * len(filter_sizes))
# Dropout
x = self.dropout(x)
# Fully Connected
logits = self.fc(x) # (batch_size, num_classes)
return logits
# Пример использования
if __name__ == "__main__":
# Гиперпараметры
VOCAB_SIZE = 10000 # Размер словаря
EMBED_DIM = 300 # Размерность эмбеддингов
NUM_CLASSES = 5 # Число классов
FILTER_SIZES = [2, 3, 4] # Размеры фильтров (2-граммы, 3-граммы и т.д.)
NUM_FILTERS = 100 # Число фильтров каждого размера
# Создаем модель
model = TextCNN(
vocab_size=VOCAB_SIZE,
embed_dim=EMBED_DIM,
num_classes=NUM_CLASSES,
filter_sizes=FILTER_SIZES,
num_filters=NUM_FILTERS
)
# Пример входных данных (batch_size=32, seq_len=50)
input_batch = torch.randint(0, VOCAB_SIZE, (32, 50))
# Forward pass
outputs = model(input_batch)
(PS: честно признаюсь, код написал ИИ 🙂)